

有的时候我们需要对一个拥有异步上下文的应用服务(比如 FastAPI 后端服务)进行代码覆盖度测试。一般来说我们会使用 coverage.py + pytest 或者是 pytest-cov + pytest 的组合。
这篇文章将以最近我写的一个考核项目为例并贯穿全文。这个项目是一个基于 FastAPI + SQLAlchemy 的后端服务,并在 tests 文件夹中存放了所有的测试实例
第一次测试
理论上,我们的测试已经涵盖了所有的 API 接口,按理说我们理应得到 90% 以上的代码覆盖率,但是由于各种原因,我们得到了这样一个结果
Coverage report: 78% (部分)
| File | Statements | Missing | Coverage |
|---|---|---|---|
| app/repositories/selection.py | 66 | 39 | 41% |
| app/repositories/course.py | 75 | 42 | 44% |
| app/api/student.py | 92 | 34 | 63% |
| app/main.py | 28 | 9 | 68% |
| app/core/config.py | 37 | 1 | 97% |
| total | 915 | 298 | 67% |
这不应该,于是我们点开了其中一个文件分析
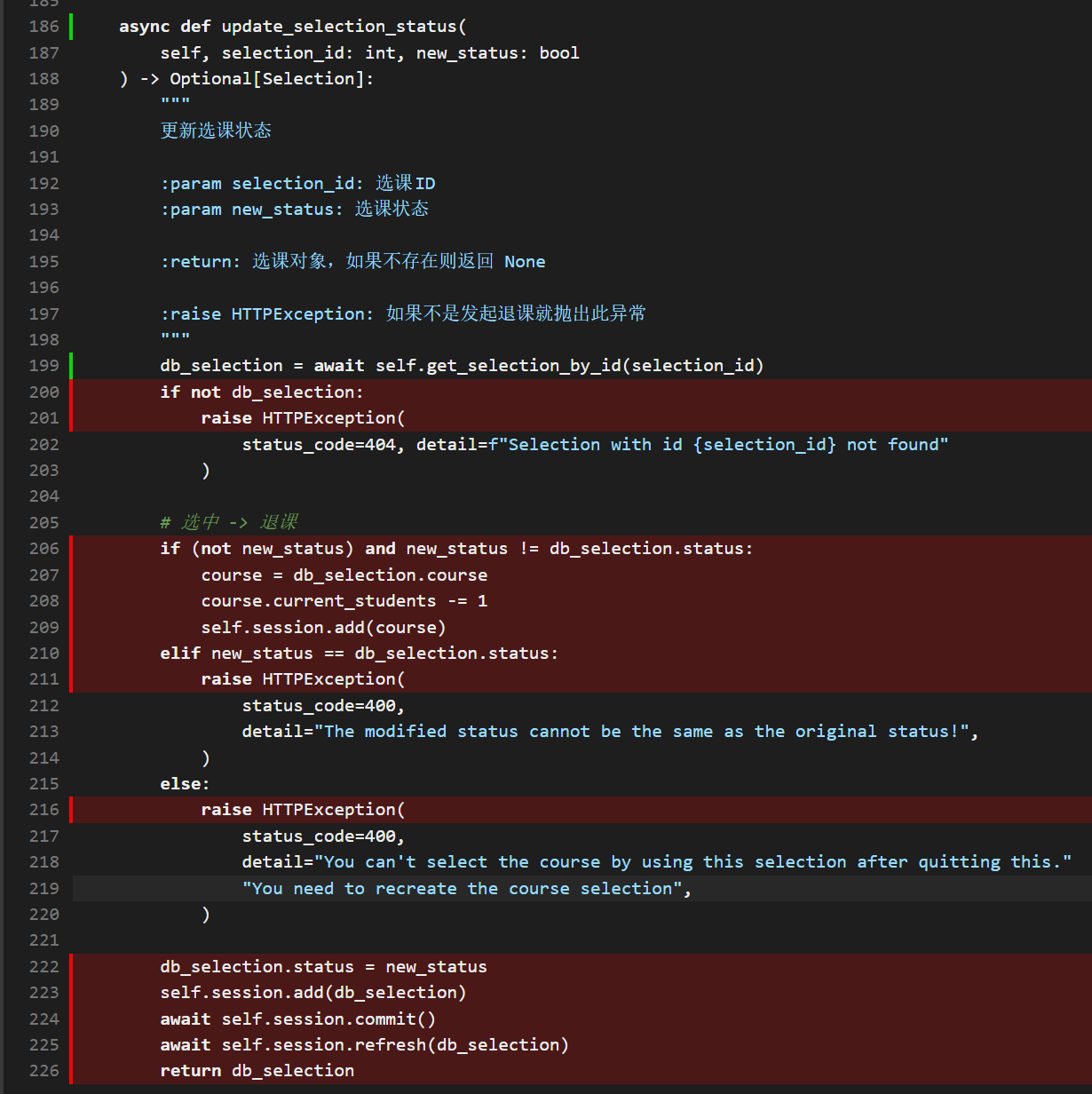
为什么 await 后面的语句都被标记为了 missing ?出于 100% 的测试成功率,我们有理由相信这些代码执行了不止一次
原因分析
如果你经常和异步应用打交道,看到上面的截图或许就能猜到是怎么回事: coverage.py 可能对于异步代码的跟踪并不是那么地好。因为 await 语句用于等待当前协程对象执行完毕,而在这期间 Python 专注于其他事务。这就让 coverage.py 误认为代码执行到这里就结束了,还没来得及等待协程对象执行完毕就把之后的代码标记为了 missing
但问题是 coverage.py 人人都在用,很多基于 FastAPI 之类的异步项目也很广泛,别人都是 100% 的 coverage,怎么到你手上就剩下个 68% ?或许你忘记了什么,于是打开文档。
然后你找到了这个
[run] concurrency
(multi-string, default “thread”) The concurrency libraries in use by the product code. If your program uses multiprocessing, gevent, greenlet, or eventlet, you must name that library in this option, or coverage.py will produce very wrong results.
See Measuring subprocesses for details of multi-process measurement.
Before version 4.2, this option only accepted a single string.
Added in version 4.0.
译: 如果你的代码中使用了如 multiprocessing、gevent、greenlet 或 eventlet 等并发库,必须在配置中明确指定。否则,coverage.py 将无法准确收集代码执行路径。
这里说的是如果你使用了多线程之类的技术或者用到了这些库,你必须在配置文件中声明这一点,不然会产生非常多错误的结果。
即使你不熟悉 FastAPI 的底层机制,你也可以对上面提到的每一个库进行 pip show 查询,最终发现,SQLAlchemy 默认依赖了 greenlet —— 这就揭示了问题的根源,你没有显式声明它。
配置 concurrency
对此,你尝试在 pyproject.toml 中添加:
[tool.coverage.run]concurrency = ["greenlet"]如果你使用 .coveragerc :
[run]concurrency = ["greenlet"]然后重新运行测试
Coverage report: 91% (部分)
| File | Statements | Missing | Coverage |
|---|---|---|---|
| app/repositories/selection.py | 66 | 13 | 80% |
| app/repositories/course.py | 75 | 15 | 80% |
| app/api/student.py | 92 | 14 | 85% |
| total | 915 | 81 | 91% |
Congratulation🎉你得到了 91% 的代码覆盖率!
在社交媒体中,有的人建议使用 concurrency = ["gevent"] ,因为这覆盖面更广,而与此同时 gevent 也依赖于 greenlet 。所以你也可以这么写,但要确保你安装了这些库。
100% 覆盖率
并非所有的测试都能覆盖代码中的每一处角落,比如入口函数和部分异常处理就无法被覆盖,而你也不想再在这些地方浪费时间撰写测试,所以我们可以在代码覆盖率计算中屏蔽它们
一般来说我们通常使用 omit 和 exclude_also 来标记要忽略的文件和代码块
排除指定文件
如下面的例子所示,[run] omit 是一个指定忽略代码文件的配置。这些文件的代码覆盖率将不纳在最终计算中
[tool.coverage.run]omit = [ "app/deps/sql.py", "app/core/sql.py", "app/main.py",]排除指定代码块
exclue_also 将指定跳过计算的代码块,它是由正则表达式组成的列表,支持忽略分支语句。
[tool.coverage.report]exclude_also = [ "logger.warning", "logging.warning", "raise HTTPException", "raise credentials_exception", "except IntegrityError",]通过以上两个配置,你应该能达到 100% 代码覆盖率的成就
结语
在这篇博客中,我尝试使用第二人称进行写作。与直接抛出结论的文章不同,在我看来,这样做能够在真实表达我解决问题的心路历程的同时,尽可能地让你学到更多。
实际上,当我在面对同样的问题时,我尝试和我的 ChatGPT 和 Gemini 朋友交流,但他们并不能给我一个满意的答案,所以我把目光投向了网络搜索引擎和在线论坛,结合文档,我才终于找到问题产生的原因和解决方式。
在 AI 发展的浪潮中,使用 AI 进行辅助开发确实是一个能够极大提高效率的手段,但与此同时这也对开发者们提出了更高的要求。他们不仅需要解读分析 AI 生成的代码与他们代码风格的差异并找出代码中可能存在的问题,并且还要掌握与 AI 交互的方式以便最大程度地发挥其性能。
所以在我眼中,尽管在裁员浪潮下许多码农们丢了工作,但程序员这个岗位永远都不会被取代。无论什么时候,总有人需要解读并为 AI 生成的代码负责。AI 永远无法达到 100% 的正确率,人类也是。只有不断学习,才能让自己走的更远。
希望这篇文章能帮你解决类似的问题,也欢迎你在自己的博客中分享你自己的解决思路或踩坑经验。祝编码愉快